
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- SQLD
- Python
- PyAudio
- OOM
- redash
- SQL
- sql 다중 like
- SQL 코딩테스트
- 커리어전환
- sql 자습
- tableau
- Dacon
- 아무말
- ubuntu
- 강성태영단어어원편
- 비전공자
- Install error
- Kaggle
- 데이터활용공모전
- BI툴
- 데이터분석가
- 리소스관리
- SQL코딩테스트
- SQL자습
- SQL 퀴즈
- 일상
- powerbi
- 2021회고
- hackerrank
- 데이터분석가 #커리어전환 #제로베이스 #데이터사이언스
- Today
- Total
GoldenGenie
데이터 분석가 커리어 전환 도전기 본문
저는 면세점 해외마케터에서 데이터 분석가로 커리어 전환을 꿈꿨습니다.
2021년 2월 퇴사 후
1년 3개월 만인 2022년 5월 커리어 전환하여 재취업에 성공했습니다.
퇴사 후 21년 7월까지는 패스트캠퍼스 (현재는 제로베이스로 이름이 바뀌었습니다)의 데이터 사이언스 강의를 수강했습니다.
학원에서 진행한 프로젝트의 내용은 <2021년 상반기 회고 - 데이터 분석가로 커리어 전환을 꿈꾸다> 에서 보실 수 있습니다.
잡 포털 사이트, 헤드헌팅, 지인 추천 등 여러 가지 루트를 통해
총 21개 기업에 지원했고, 그 중 7 개 회사 서류 합격을 거쳐 면접의 기회를 얻었으며
감사하게도 3개의 기업에 합격하여, 그 중 하나인 쿠팡 풀필먼트 서비스에 Business Analyst 포지션으로 입사하기로 결정했습니다.
당차게 퇴사를 결심한 만큼 좋은 커리어 전환의 사례를 만들고 싶었습니다.
결론적으로는 패스트캠퍼스(제로베이스) 수강 그리고 취준 기간 동안 인턴과 병행한 다양한 기업 프로젝트가 실력향상에 큰 도움이 되었다고 말씀드리고 싶습니다. 수업을 듣고 데이터 전처리, 머신러닝을 직접 해보는 연습도 중요하지만, 프로덕트에서 이런 결과물이 어떻게 활용되는지 고민하고 기획과 개발에 모두 참여하는 것이 실무적으로 좋은 경험이 되기 때문입니다.
그래서 이 글에서는 학원 수강 그 이후 취업 준비 기간 동안에 진행했던 프로젝트를 중점적으로 소개드립니다.
알고캠핑
학원 수강생들 중 마음 맞는 분들과 총 4명의 팀을 꾸려 도전한 프로젝트였습니다.
저는 알고캠핑의 추천 알고리즘과 서비스/사업 기획 전반을 담당했습니다.
알고캠핑은 알고리즘 추천 맞춤형 캠핑장 검색 기능을 제공하는 Web, APP 서비스입니다.
유저의 설문 결과를 기반으로 나만의 캠핑 취향을 찾을 수 있도록 하는거죠!


아래는 알고캠핑의 검색 결과 페이지 일부 입니다.
회원가입 설문 결과에 따라 최상단 추천 캠핑장 배너와 문구는 모두 상이하며, 새로고침할 때 마다 달라집니다.
또한 추천 태그로 쉽고 빠르게 검색이 가능합니다.

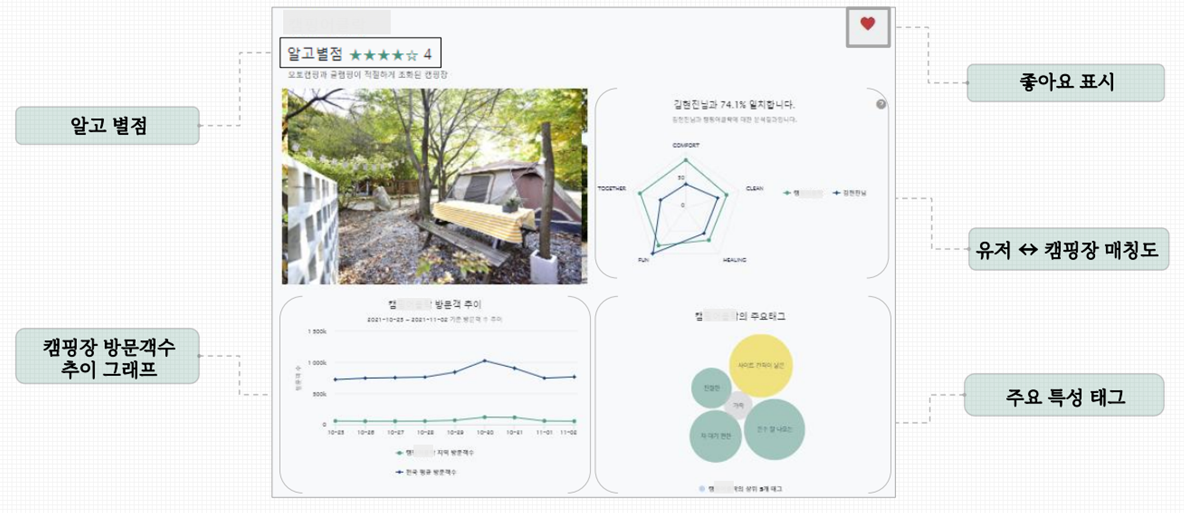
추천 로직과 상세 기능을 설계하기 위해 많은 도전과 고민이 있었습니다.
캠핑장 추천을 위해 고캠핑 API 데이터와 포털사이트 리뷰를 크롤링해서 활용했으며
자연어 처리를 통해 캠핑장 주요 특성별로 클러스터링을 진행했습니다.
이 캠핑장 군집으로 추천 시나리오를 짜고, 그에 상응하는 설문 응답 유저에서 보여주는 방식입니다.

한국관광공사와 카카오에서 주관한 <관광데이터 활용 공모전>에 출품했고
기획서 제출부터 제품 개발까지 21년 6월부터 10월까지 5개월이 걸렸습니다.
제 프로젝트 중 가장 많은 시간과 노력을 들였던 아이 입니다.
결과적으로 우수상이라는 뿌듯한 결과를 얻을 수 있었고,
유튜브 실시간 라이브로 IR피칭에 참여하는 재미있는 경험도 할 수 있었습니다!


데이터 분석가 직무에 딱 맞는 프로젝트는 아닐지 몰라도, 프로덕트 차원에서 데이터를 어떻게 활용하는게 좋을지 기획 단계부터 고민하고, Web과 APP으로 결과물이 나오도록 내부 알고리즘을 직접 코딩해서 구현하는 모든 과정 (python class 모듈화...github 잘 사용하기...API 데이터 끌어오기...MySQL DB 설계 등등...)이 큰 도움이 되었습니다.
5개월 이라는 꽤 긴 시간 동안 함께 고생한 팀원들과 매주 저희의 고민을 듣고 멘토링해주신 민형기, 박두진 강사님께 다시 한 번 감사의 말씀을 드리고 싶네요 :)
패스트캠퍼스 (제로베이스) 에서 머신러닝, 딥러닝을 가르쳐주셨던 민형기 강사님의 도움으로 일본 시장의 엔터테인먼트 분야 스타트업인 S사에서 인턴 생활을 하게 되었습니다. 데이터 사이언스에 관심 많은 S사 대표님은 음원, 영상, 웹툰 등 다양한 분야에서 머신러닝을 접목시킬 주제를 제공해주셨습니다.
민형기 강사님의 코칭과 함께 저를 포함한 3명이 데이터 사이언스 팀원으로서 프로젝트를 수행하며
매주 ZOOM으로 진행 상황도 공유하고 활발한 피드백을 주고 받으며 참 많이 성장했습니다~
음원 유사도 평가 미니 서비스 기획
음악 듣는 걸 정말 좋아하는 저는, 음원 데이터로 머신러닝을 해볼 기회가 있다는 말에 흥미를 느끼며 처음 이 프로젝트에 합류하게 되었습니다.
객관적인 일정 기준 보다는 전문가의 판단에 표절 여부를 결정하는 판례가 대부분인 것을 보면 음원의 표절 여부를 알기란 결코 간단하지 않습니다. 여기에서 착안한 것이 첫 번째 프로젝트 주제인 "음원 유사도 평가" 입니다.
저희 팀은 음원을 수치형 데이터로 변환하여 유사도를 구하기도 하고, 스펙트럼 이미지로 변환하여 딥러닝을 시도해보기도 했습니다.

음원을 58개의 수치형 데이터로 바꾸고, 이를 활용하여 음원 간의 코사인 유사도를 구하는 방식으로 간단한 유사도 평가 미니 서비스를 기획했습니다. 회사 구성원들이 직접 접속하여 음원을 들어보고 그 유사도를 정성, 정량적으로 평가할 수 있도록 프로토타입을 만들었습니다. 사내 백엔드, 프로트엔드 개발자와 협업하여 MySQL 데이터베이스 기획과 미니 서비스 런칭까지 해볼 수 있어 재미있는 시간이었습니다.
음원 분류
고양이는 야옹, 강아지는 멍멍, 사람은 어쩌구저쩌구..
이미 상용화되어 많은 가정집 거실에 있는 AI 스피커는 음성을 인식하고, 소리를 들려주면 어떤 소리인지 구분해내는 기능도 꽤 자주 접할 수 있습니다.
이번 프로젝트는 가볍게 동물 소리를 구분하는 것부터, 사람 목소리 그리고 생활 소음 등을 머신러닝으로 구분해내는 것이 미션이었습니다.
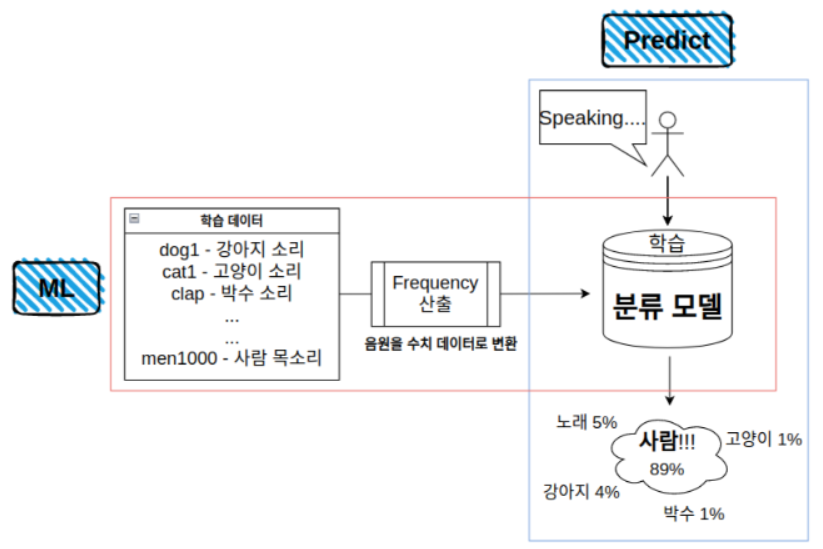
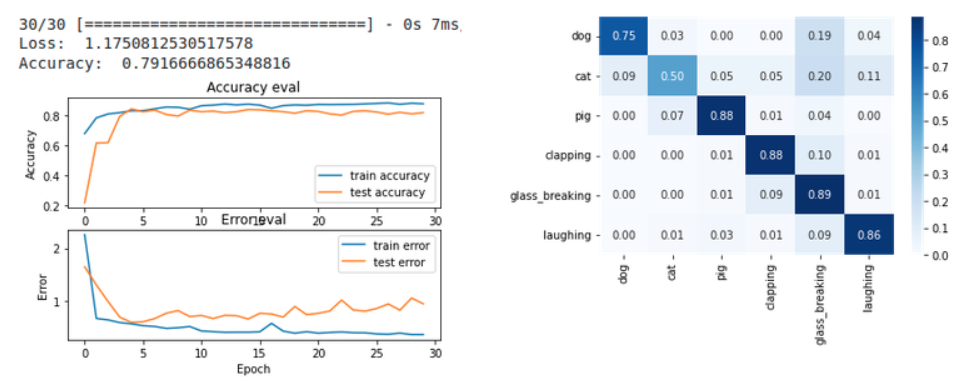
구분점이 명확한 동물 간의 분류는 용이하게 정확도 85% 이상을 달성하였지만, 구분하고자하는 라벨이 많아질 수록 데이터 수급과 정확도 제고에 많은 시도가 있었습니다.
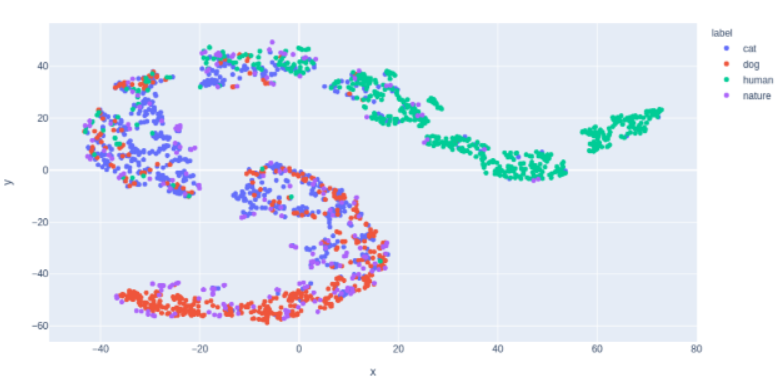
이 때 librosa 라는 모듈을 굉장히 애용하며, 모듈 내 다양한 기능과 파라미터를 다뤄보는 재미있는 시간이었습니다. 실제로 파라미터에 따라 분류의 정확도가 꽤 달라져서 파라미터 튜닝이 결과에 영향을 미치는 것을 보고 흥미로웠습니다.
음원에 대한 이해도가 없다보니, 유튜브로 음원의 이론에 대해 공부를 계속 병행했습니다. 특히 음원 처리 방식인 stft(short time fourier transform) 를 chroma 12음계로 나타낸 chroma_stft 가 제일 기억에 남네요. n_fft와 hop_length 라는 파라미터를 조정함에 따라 정확도가 달라졌기 때문인데요. 예를 들면, 사람 목소리 간의 분류는 n_fft가 512일 때, 그 외 생활 소음 포함 폭 넓은 라벨들 간의 분류는 n_fft가 디폴트값인 2048일 때 성능이 제일 좋았었습니다.


실제 음성 분류 모델을 동영상에 초 단위로 반영하여 결과물 영상을 구성원들께 공유하며 뿌듯했던 기억이 있습니다. 모델링 과정에서도 코딩 레벨과 음원 지식 면에서 많은 배움이 있었고, 더불어 그 결과물을 쇼잉하는 과정에서도 코딩으로 자막달기, 마이크로 초 단위의 결과물을 매끄럽게 필터링하여 반영하기 (low-pass filter 활용 - 민형기 강사님 블로그 참조) 등등에서 많은 경험을 할 수 있었습니다.
Audio transfer learning - yamnet
음원 분류 정확도를 높이고 라벨을 늘려가기 위해 다양한 시도를 하던 중 말씀해주셨습니다.
팀원분이 "구글에 음원도 전이학습할 수 있는 pre-trained model 이 있습니다!!"
구글 느님께서 친절하게도 사전 학습된 모델 뿐 아니라 튜토리얼 까지 제공해주고 있기에,
제가 원하는 라벨에 맞춰서 새로 학습시켜 다양한 모델을 만들어볼 수 있었습니다.
50개 라벨의 정제된 음원 데이터셋을 제공하는 ESC50 을 활용하여 모델링을 해보았는데요
생각보다 결과가 괜찮아서, 오픈소스로 모델과 데이터를 공유해주는 많은 분들께 감사해지는 순간이었습니다.

POS 데이터 자연어처리 모델링
이 프로젝트 또한 민형기 강사님의 소개로 감사하게도 평소 관심있던 페이먼트사인 F사의 프로젝트 기회를 얻어 진행하게 되었습니다. POS 데이터를 활용하여 메뉴 이름을 보고 어떤 카테고리의 메뉴인지 분류해내는 과제 였습니다.

알고캠핑 프로젝트 때 경험한 자연어처리는 문장이나 글의 비교적 큰 단위의 자연어였다고 하면,
이번 프로젝트에서는 메뉴명이기에 매우 짧다는 특징이 있었습니다.
Subwords를 사용하는 FastText 모듈을 활용하여 Out of Vocabulary 문제를 해소하려고 노력했습니다.
정제되지 않은 10만 개 이상의 데이터를 머신러닝 모델로 빠르게 라벨링하고, 90% 이상의 accuracy로 분류 모델을 만들어 볼 수 있어 재미있는 프로젝트였습니다.
맺으며..
이렇게 커리어 전환을 위해 쉼 없이 달려왔던 지난 1년 3개월 간을 빠르게 돌아보았습니다.
심리적으로 체력적으로 지치는 순간도 정말 많았습니다.
그럴 때마다 비전공자도 데이터 사이언스 배울 수 있고, 또 성공적으로 커리어 전환할 수 있다 는 걸 제 자신에게 보여주고 싶었습니다.
부족함 많은 학생인 저에게 따뜻한 조언과 많은 기회를 주신 PinkWink 민형기 강사님께 다시금 감사 인사드립니다.
강사님과 함께 매주 성과 공유하는 미팅에서 다양한 각도에서 고민하고 피드백 주고 받을 수 있어 참 좋았는데요,
출근을 하더라도 데이터 분야에 대한 자유로운 토론식 미팅이 그리울 것 같습니다.
직장 생활에 적응하는대로 얼른 다시 스터디원을 모집해서 이런 활동을 이어가고 싶어요 :)
또한 의지가 박약해질 때 마다 저보다도 저를 더 믿어준 가족과 남자친구도 고맙습니다.
많은 분들의 도움을 받았기에 저 또한 제 도전 과정이 커리어 전환을 꿈꾸는 누군가에게 조약돌 같은 도움이 되길 바랍니다.
이렇게 비즈니스 분석가로서 첫 발을 내딛게 되었습니다.
앞으로 현업에서 보고 느끼는 점 많이 공유하며 계속 성장해나가고 싶습니다👩💻
'Work==Life > 커리어' 카테고리의 다른 글
| 2021년 상반기 회고 - 데이터 분석가로 커리어 전환을 꿈꾸다 (0) | 2022.01.03 |
|---|
